
언어의 기초사항
1. 자바 주석문1) C, C++ 언어 스타일의 주석문자바 언어는 주석문을 자바 source 코드 내에 프로그램에 수행에 불필요한 코드를 삽입할 수 있습니다.
주석문을 사용하면 source 코드를 설명하는 코멘트를 첨가할 수 있습니다.
C 스타일 주석, 여러 줄에 걸쳐서 사용할 수 있습니다. 형태는 다음과 같습니다.
/* */
C++ 스타일 주석, 한 줄을 주석으로 사용할 때 편리합니다. 형태는 다음과 같습니다.
//
2) javadoc 주석문javadoc 주석문을 사용하면 해당 class의 상속관계를 표현하는 계층도나 class 멤버들에 대한 설명 등을 html 파일 형태로 제공하는 문서(document)를 만들 수 있습니다. 이러한 문서는 다음과 같이 source프로그램을 javadoc명령에 의해 실행시켜 생성합니다.
javadoc Hello.java
다음은 javadoc 명령 실행시 생성되는 html 파일들의 리스트입니다.
Loading source file Hello.java...
Constructing Javadoc information...
Building tree for all the packages and classes...
Building index for all the packages and classes...
Generating overview-tree.html...
Generating index-all.html...
Generating deprecated-list.html...
Building index for all classes...
Generating allclasses-frame.html...
Generating index.html...
Generating packages.html...
Generating World.html...
Generating serialized-form.html...
Generating package-list...
Generating help-doc.html...
Generating stylesheet.css...
index.html이나 index-all.html 또는 Hello.html 파일을 열어서 보면 해당 source 파일의 상속관계, 구성 멤버들에 대한 정보를 알 수 있습니다.
2. 자바 source file 구조1) 파일 이름 만들기자바 파일 이름은 반드시 .java 확장자로 끝나야 합니다. (jav 또는 JAVA가 되지 않게 꼭 주의하셔야 합니다.)
그리고 만약 source 안에 public인 top level class가 있다면 파일 이름은 반드시
public인 class 이름 .java
로 하셔야 합니다.
public class Hello {
public static void main(String[] args) {
System.out.println("Hello World");
}
}
위와 같은 경우 저장할 파일 이름은 반드시 Hello.java로 하여야만 하는 것입니다.
public class Hello {
public static void main(String[] args) {
System.out.println("Hello World");
}
}
class World {
void print() {
System.out.println("World");
}
}
위의 source 파일 이름은 Hello.java 이겠지요?
자바는 컴파일된 후 실행 파일 이름이 .class의 형태로 나옵니다.
따라서 위의 source 프로그램이 컴파일되면 Hello.class 와 World.class 두 개의 파일이 만들어집니다.
물론 이때 Java interpreter와의 실행에는 main 메소드를 가지고 있는 Hello.class를 사용하여야만 하겠지요.
public class Hello {
public static void main(String[] args) {
System.out.println("Hello World");
}
}
public class World {
void print() {
System.out.println("World");
}
}
위와 같은 source 프로그램 코딩은 잘못된 것입니다. 왜냐하면 public은 두 개인데 파일은 하나 밖에 만들 수 없으니까요. 만약 두 class 모두 다 꼭 public이어야만 한다면 파일을 따로 만들어야만 합니다.
class Hello {
public static void main(String[] args) {
System.out.println("Hello World");
}
}
class World {
void print() {
System.out.println("World");
}
}
위의 source 프로그램과 같이 public인 class가 하나도 없는 경우라면 파일 이름은 어떤 class의 이름을 사용하여도 상관없습니다.
class Hello {
public static void main(String[] args) {
System.out.println("Hello World");
}
}
public class World {
void print() {
System.out.println("World");
}
}
위의 source 파일같은 경우 Hello.java로 저장하면 오류가 발생합니다. public이 있는 World.java로 저장하여 컴파일하고 실행시에는 main 메소드를 가진 Hello로 실행합니다.
2) 소스 파일의 기본 구조source 파일의 구조는 문장에 따라서 순서가 정해져 있습니다.
package 선언문
import 문
class 정의문
즉, 위와 같이 3개의 top level element는 순서에 의해 사용되어야만 하는 것입니다.
이 중 package, import 문장은 꼭 사용하지 않을 수도 있지만, 필요에 따라 source 안에 사용해야 한다면 반드시 위의 순서에 따라 주어야 합니다.
package my.firstpack;
import java.awt.*;
import java.util.*;
public class Hello {
public static void main(String[] args) {
System.out.println("Hello World");
}
}
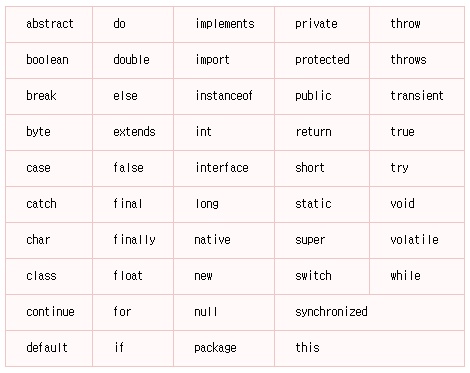
4. Keyword 와 Identifier1) Keyword 리스트
C 프로그래머를 위한 몇가지 주의사항은
C에서 많이 쓰셨던 sizeof operator가 자바에는 없다는 것입니다. 이 operator는 자바에서 더 이상 존재의 의미가 없기 때문에 빠지게 된 것.
NULL, TRUE, FALSE 같이 C에서 keyword는 아니지만 #define 문으로 정의해서 사용하던 단어들이 자바에서는 소문자로 바뀌어서 null, true, false와 같은 keyword로 사용됩니다.
자바는 goto, const 같은 단어들을 실제로 구현은 안했지만 keyword로 등록 시켜놓았습니다.
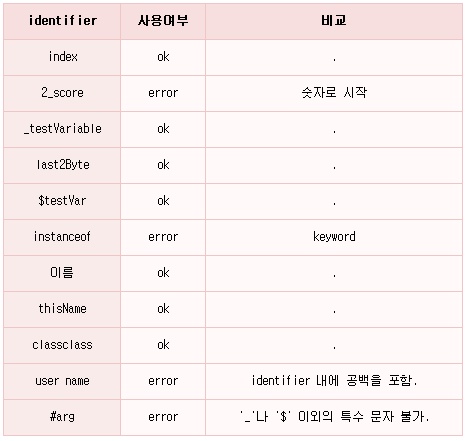
2) Identifier를 만드는 규칙자바 identifier는 class 이름, 메소드 이름, 변수 이름, 문자 label 등에 사용됩니다.
자바는 일반 문자, 숫자, 그리고 특수 문자('_' 와 '$')등을 조합하여 identifier를 만들 수 있습니다. 이때 반드시 첫번째 문자는 숫자가 아닌 단어로 시작해야 하며 특수 문자도 첫번째 문자로 올 수 있습니다.
자바 keyword는 identifier로 사용할 수 없습니다. 그러나, keyword를 포함하는 단어는 identifier로 사용할 수 있습니다. identifier는 공백을 포함할 수 없습니다.
자바는 ASCII코드를 넘어선 Unicode를 지원하기 때문에, 일반 문자로 'a'-'z', 'A'-'Z' 뿐만 아니라 한글도 사용할 수 있게 되어 identifier를 한글로 만들 수도 있습니다.
그리고 identifier들은 case sensitive하고 실제 maximum length에 대한 제한은 없습니다.
5. 코딩 Convention1) class 이름과 interface 이름 정하기class나 interface의 이름은 첫번째 문자를 항상 대문자로 시작해야 합니다. 만약 두 단어 이상으로 만들어져 있으면 단어 사이를 대문자로 연결합니다. class 이름은 보통 명사로 만듭니다.
class 이름 예 : Button, Frame, Applet, Thread, MenuBar
interface 이름 예 : Runnable, LayoutManager, AppletContext
2) 메소드 이름과 변수 이름 정하기메 소드 이름과 변수 이름은 문장처럼 여러 단어가 올 수 있는데, 항상 첫 번째 문자는 소문자로 시작하고 단어와 단어의 연결은 뒷 단어를 대문자로 시작합니다. 메소드 이름은 보통 동사로 시작합니다. 변수 이름은 보통 명사로 되어있습니다.
메소드 이름 예 : getImage(), getDocumenttBase(), setBackground()
변수 이름 예 : height, width, pointSize
3) 상수 이름 정하기Primitive Data Type 변수에 값을 할당하기 위해 사용하는 상수는 모두 대문자로 표시하고 단어 사이는 _(underscore)로 연결합니다. Reference Data Type일 경우는 대소문자를 다 사용합니다.
Primitive Data Type 상수 예 : BOLD, ITALIC, CROSSHAIR_CURSOR
Reference Data Type 상수 예 : black, darkGray, UndefinedProperty
6. Data Type(데이터형)과 Literal1) Primitive Data Type (기본 데이터형)자바에는 Primitive Data Type과 Reference Data Type(참조 데이터 형 = Object Reference Data Type)이라는 두 가지의 Data Type이 있습니다.
Primitive Data Type의 종류에는 boolean, char, byte, short, int, long, float, double 등 8개가 있습니다. Primitive Data Type 으로 선언된 변수는 실제 값을 갖게 됩니다.
이와는 달리 Reference Data Type으로 선언된 변수는 어떤 값이 저장되어 있는 메모리의 주소를 갖게 됩니다.즉, 블럭 구조로 여러 다른 Data Type의 값들을 모아놓은 곳의 base address를 갖게 되고, 이 정보를 바탕으로 여러 값을 얻어낼 수 있으므로 Reference(참조)라는 말을 붙인 것입니다. Reference Data Type에는Array(arrary), class, interface가 있습니다.
자바의 모든 Primitive Data Type들은 Java Virtual Machine(JVM)을 따르기 때문에platform에 따라 크기가 바뀌지 않습니다. 대표적인 경우가 int입니다. C 언어에서는 platform에 따라 int크기가 다양하게 바뀐다는 것을 알고 계시죠? 하지만 자바는 그렇지 않다는 것입니다. 아마도 이 점이 sizeof가 필요 없는 이유 중 하나일 것입니다.
boolean Data Type 자 바는 C에는 없는 boolean Data Type이 존재합니다. boolean Data Type으로 선언된 변수는 true와false 두 가지 값만을 가질 수 있습니다. true와 false는 반드시 소문자로 코딩해야한다는 점을 잊지 마십시오.
char Data Type 자바의 char Data Type은 ASCII를 지원하지 않고 2 byte Unicode를 지원하기 때문에 16 bit의 양의 정수로 표현 되어집니다.
즉, 실제 가질 수 있는 값의 범위는 0 부터 2^16 - 1 까지인 것입니다. (unsigned라는 뜻이지요.)
byte, short, int, long (Integral) Data Type 모든 Integral Data Type은 signed입니다. 즉, 2's complement 방식으로 표현되는 것이지요.unsigned integral type은 지원하지 않습니다. Integral Data Type들의 표현 값의 범위는 다음과 같습니다 :
float, double (Floating point) Data Type Floating point Data Type은 IEEE754 Spec.에 따라 표현되어 있고 역시 platform에 상관없이 구현되어 있습니다. float Data Type은 32 bit 크기의 실수를 표시할 수 있으며, double Data Type은64 bit 크기의 실수를 표현할 수 있습니다
2) 사용되는 literalboolean literal literal은 소문자인 true, false 두 가지 종류 밖에 없습니다.
boolean isFull;
boolean beOk = false;
isFull = true;
char literal char data type에 대한 literal은 C에서와 마찬가지로 single quotes에 둘러싸인 문자로 표현됩니다.그리고 코딩시 입력하기 어려운 문자 값을 넣기 위한 escape sequence를 자바도 '\n' 형식으로 지원합니다.
char ch1 = '\n';
char ch2 = '\r';
char ch3 = '\t';
char ch4 = '\u88ab'; // Unicode 표현
char ch5;
ch5 = 'a';
여기서 특이하다면 '\u' 라고 할 수 있는데, \u 뒤에는 2 byte Unicode 즉, 4개의 hexa value가 올 수 있습니다. '\u88ab'의 의미는 실제 Unicode 88ab번의 문자라는 것 입니다.
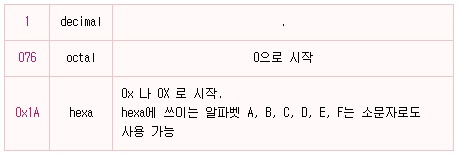
Integral literal Integral Data Type으로 선언된 변수가 가질 수 있는 Integral literal은 C와 마찬가지로 decimal, octal, hexa 의 3가지 표현으로 나타나집니다.
그리고 위의 숫자들과 같이 특별한 suffix가 없으면 모두 int type으로 간주합니다. 만약 int 크기가 아닌 long 크기를 표현하고 싶다면 숫자 뒤에 l 또는 L을 붙여주면 됩니다.
Floating point literal 만약 어떤 숫자 literal이 decimal point(.) 나 expornent part(e, E)를 사용하여 표현되어 지거나 또는 suffix로 f, F, d, D 중 하나를 포함하고 있으면 Floating point literal로 처리되게 됩니다. suffix를 사용함에 있어 f 나 F 없이 사용된 literal은 무조건 double(64 bit) 크기로 인식이 되어버립니다.
String literal 자바의 String Data Type은 class로 만들어져 있는 Reference Data Type 이지만 연속적인 문자열을 표시하기 위한 literal이 제공되고 있습니다. 물론 unicode로 만들어지고 double quotes를 사용하여 둘러싸게 되어 있습니다.
String msg = "이 문자열은 테스트용 입니다.";
7. 변수 선언 : 기본 개념1) 자바의 변수 선언메 모리상의 데이터를 프로그램에서 접근하기 위해서는 실제 데이터를 나타내는 변수가 있어야 합니다. 변수를 이용하여 프로그래머는 메모리상에 데이터를 저장하고 반대로 저장된 데이터를 불러와 사용하기도 합니다. 즉, 변수는 프로그래머가 메모리상의 데이터에 접근하기 위한 방법이며 데이터와 1 : 1 대응됩니다.
변수를 사용하려면 먼저 변수 선언이라는 절차가 필요합니다. 변수 선언이란 자바가상머신(JVM)에게 데이터를 저장하기 위한 메모리를 할당하라는 의미입니다. 그러기 위해선 데이터 타입이 필요합니다. 데이터 타입에 따라 그 데이터가 필요로 하는 크기만큼의 메모리를 할당합니다. 두 번째로는 변수를 다른 변수와 구별할 수 있는 이름이 있어야 합니다. 이것을 변수명이라 합니다.
자바에서는 변수 선언시 다음과 같은 구조를 가집니다.
데이터 형 변수이름;
예를 들어, 논리형 데이터를 갖는 itsTrue라는 변수를 선언한다면 아래와 같은 문장으로 표현합니다.
boolean itsTrue;
이 때, 데이터 형은 자바에서 정해진 타입 중의 하나로 선언하고 변수이름은 변수이름의 coding convention에 따라 정의할 수 있습니다.
2) Primitive Data Type 변수 선업법Primitive Data Type들은 C에서와 마찬가지로 선언과 동시에 자신의 크기에 맞는 메모리 할당이 동시에 일어납니다.
3) Referance Data Type 변수 선언법boolean, char, byte, short, int, long, float, double과 같은 Primitive Data Type은 이에 대한 정보가 컴파일러에 내장되어 있어 선언과 함께 정의된 만큼의 메모리를 생성하게 됩니다.
하지만 Array, class, interface 등과 같이 그때 그때마다의 정의에 따라 메모리 할당에 필요한 정보가 달라지는 Reference Data Type으로 선언될 변수는 선언과 생성이 분리되어 있습니다. C와 비교해 보자면pointer 처럼 선언 후 따로 memory 할당을 해줘야 한다는 것이지요. 물론 할당에 관련된 기능이 따로 있습니다.C++처럼 new라는 operator를 사용해서 dynamic하게 heap으로부터 할당해서 쓰게 되어 있습니다.
import java.util.*;
class TestVar {
public static void main(String[] args) {
String msg; // 라인 1.
msg = new String("sample 1"); // 라인 2.
}
}
String은 class type입니다. 그러므로 라인 1번으로는 선언만 이루어진 것이지요. 따라서 라인 2번과 같이 String object를 만드는 (메모리 할당) 작업이 병행되어야 합니다.
import java.util.*;
class TestVar {
public static void main(String arg[]){
String msg = new String("sample 2");
}
}
위와 같이 선언과 생성이 한줄로 표현될 수도 있습니다. 앞서 Reference Data Type으로 선언된 변수는 어떤 값이 저장되어 있는 메모리의 주소를 갖는다고 했던 것 기억 나시죠? 이 개념은 마치 C에서의 pointer 개념과 거의 유사한 것으로 분명한 차이점은 C에서의 pointer 변수는 arithmetic 연산이 가능했던 반면 자바의 Reference Data Type 변수는 이러한 연산이 불가능하다는 것입니다.
import java.util.*;
class TestVar {
public static void main(String arg[]){
String msg = "sample 3";
}
}
특별히 String은 위의 예문과 같이 new를 사용하지 않고 literal만으로도 내부에서 필요한 object가 만들어지게 되어 있습니다.
import java.util.*;
class TestVar {
public static void main(String arg[]){
Date today = new Date();
System.out.println("Today is:" + today);
}
}
위와 같이 class type인 Date로 변수를 선언하고 생성하면 시스템에 의해 오늘의 날짜 값이 변수에 저장되게 됩니다.
8. Array에 관하여1) Array 선언법선 언은 컴파일러에게 "이 변수는 Array type이다"라는 것을 알려주는 것이겠죠? 선언시 Array 표시 기호로는 C처럼[]를 사용합니다. 그리고 아시다시피 Array는 특정 type의 element들을 연속적으로 갖는 것이기 때문에 반드시 그element의
type이 무엇인지 알려 주어야만 합니다.
int intArray[];
위의 선언문은 int type의 element를 갖는 Array에 대한 것 입니다. 코드에서 보는 것처럼 C와 비슷한 방식으로 선언이 이루어 집니다. 하지만 다른 점은 [] 안에 몇 개의 element가 와야할지 크기 지정을 하지 않는다는 것입니다. 왜냐하면 크기에 대한 정보는 선언할 때 필요한게 아니라 메모리를 생성할 때 필요하기 때문입니다. 즉, 선언에서는 단지"어떤 어떤 type의 Array이다." 라는 것만 알려주는 것입니다.
double [] dArray, otherArray;
위와 같이 [] 표시 기호를 꼭 변수 뒤가 아닌 앞쪽에 붙여도 상관 없습니다. 단, 이렇게 선언하면 dArray뿐만 아니라 뒤에 연속적으로 나오는 변수명도 Array로 취급됩니다. 따라서 위와 같은 경우 otherArray 변수도double type element를 갖는 Array로 선언된 것으로 취급되는 것입니다. 하지만 다음과 같은 선언은 변수msgArray는 Array이지만 str은 단지 String class type 변수일 뿐입니다.
String msgArray[], str;
반드시 주의하실 것은 선언할 때 [] 안에 절대 size 정보를 주지 말아야 한다는 것입니다. 잊지 마세요!!!
2) Array 생성법 (메모리 할당하기)이 번에는 어떤 type element를 갖는 Array로 선언된 변수에 실질적인 메모리를 할당하는 방법에 대해 알아보겠습니다.이러한 생성 역시 new 연산자를 이용하게 됩니다. 생성된 모든 Array들은 length 라는 member 변수를 갖게 되는데, 이 member 변수 length에는 element가 몇 개 생성되었는지에 대한 정보가 저장됩니다. sizeof연산자가 필요없는 또 다른 이유라 할 수 있겠죠.
다음은 선언과 함께 new operator를 사용하여 arrary을 생성하는 예문입니다.
int intArray[] = new int[100];
이와 같이 element 갯수에 대한 정보는 new 연산자를 사용 할 때 지정하게 됩니다. 위의 경우 선언과 생성이 완료되면 intArray[0]부터 intArray[99]까지 총 100개의 element를 int type 변수로 사용할 수 있는 것이지요. 이 때 intArray.length에는 100의 값이 저장될 것입니다.
다음은 선언과 생성을 별도로 코딩한 것입니다.
double [] dArray, otherArray;
dArray = new double[100];
otherArray = new double[200];
int i = 5; // 라인 1.
String msgArray[] = new String [i]; // 라인 2.
msgArray[0] = new String("first msg"); // 라인 3.
msgArray[1] = new String("second msg");
msgArray[2] = new String("third msg");
msgArray[3] = new String("forth msg");
msgArray[4] = new String("fifth msg");
앞에서 언급한 것처럼 Array element 갯수는 new 연산자를 사용하는 생성 부분에서 정의되기 때문에, element 갯수에 대한 정보는 위의 예문과 같이 변수화될 수 있는 것입니다.
라인 1과 라인 2의 선언과 생성을 통해 msgArray[0]부터 msgArray[4]까지 5개의 element가 String class type으로 사용할 수 있게 되었습니다. 이 때 (7. 변수 선언 : 기본 개념에서 학습한 바와 같이) String class type은 Reference Data Type이므로 라인 3 이하의 문장들과 같이 String object를 생성하는 작업이 필요함은 이미 다 알고 계시겠죠?
3) Array 초기화
Array는 다음과 같이 한 줄로 선언과 생성, 초기화를 동시에 만들어 낼 수도
있습니다. (잘 익혀두세요!!!)
int intArray[] = {100, 200, 300};
float fArray[] = {1.1f, 2.2f, 3.3f, 4.4f};
String sArray[] = {"hello", "SCJP", "exam"};
이때 Array들은 초기화한 개수만큼 element들이 생성됩니다. 즉, intArray.length는 3의 값을 갖게 되는 것입니다.
또한 다음과 같이 반복문을 이용하여 생성된 Array에 초기값을 할당할 수도 있습니다.
int score[] = new int[3000];
for (int i = 0; i < score.length; i++)
score[i] = i ;
이 평범해 보이는 문장에서 살펴볼 사항은 반복 횟수에 대한 것입니다. 즉, 생성한 Array의 length라는member 변수를 이용함으로써, 만약 나중에 new 문에서 지정한 element의 갯수가 변하더라도 초기화에 사용된 조건문을 일일이 확인 하지 않아도 되니까 그만큼 안전한 프로그램이 될 수 있을 것입니다.
자바는 C처럼 array boundary를 넘어서는 코드를 만들 수 있게 놔두지 않습니다. 물론 컴파일에서는 별 탈이 없겠지만, 실행에서는 array boundary를 벗어나면 이를 잡아내 주게 되어 있습니다.
int score[] = new int[3000];
for (int i = 0; i < 3001; i++)
score[i] = i ;
위와 같은 코드가 컴파일되어 실행된다면 i가 2999일 때 까지는 제대로 잘 실행되어 처리되다가, i가 3000을 갖고score를 access 하는 순간 boundary를 벗어나 다른 메모리 영역을 침범하는 것이 아니라 바로
ArrayIndexOutOfBoundsException
이라는 예외(exception)를 발생시켜 이를 처리 할 수 있게 해주는 것입니다. (예외(exception)에 대한 자세한 내용은 7장에서 다룹니다.)
4) 다차원 Array자바에서도 2차원 이상인 arrary을 만들 수 있습니다.
int twoDimArray[][] = new int[4][10] ;
이러한 선언과 생성은 twoDimArray[0][0]부터 twoDimArray[3][9]까지 4 by 10의 정사각형을 연상시키는 40개의 element를 만들 것입니다. 그런데 만약 2차원 arrary을 사용함에 있어 각각의 크기를 다르게 하고 싶다면 어떻게 해야 할까요?
int twoDimArray[][]; // 라인 1.
twoDimArray = new int[4][]; // 라인 2.
twoDimArray[0] = new int[5]; // 라인 3.
twoDimArray[1] = new int[10]; // 라인 4.
twoDimArray[2] = new int[3]; // 라인 5.
twoDimArray[3] = new int[7]; // 라인 6.
for (int i = 0; i < twoDimArray.length; i++)
for (int j = 0; j < twoDimArray[i].length; j++)
twoDimArray[i][j] = 0;
라인 2에서는 element 갯수가 4개인 2차원 Array를 생성한 것이고 라인 3,4,5,6에서는 이렇게 생성된 각 element가 필요로 하는 만큼의 Array를 생성하는 것입니다.
for 문으로 이루어지는 초기화 작업에서 각각의 반복 횟수로 사용된 값들을 의미있게 살펴보세요.twoDimArray.length는 4가 될 것이고 twoDimArray[0].length는 5 twoDimArray[1].length는 10 twoDimArray[2].length는 3 twoDimArray[3].length는 7이 될 것입니다. 이렇게 하면 2차원 Array를 꼭 정사각형이 아닌 dynamic한 형태로 사용할 수 있겠죠?
9. class 기본 개념1) main 메소드 정의하는 법자바에서의 메소드는 독립적으로 호출될 수 없으며 반드시 객체의 일부로서만 호출이 가능합니다. 그러나 예외적인 메소드가 있는데 바로 main 메소드입니다. 이 메소드는 자바 프로그램을 실행할 때 자바가상머신(JVM)에서 호출되는 최초의 메소드입니다.
java 실행할 class이름
의 명령으로 class를 실행할 때 자바가상머신(JVM)에서 class 이름으로 지정된 class에 포함된main 메소드를 호출합니다.(앞서 살펴본 바와 같이 애플릿의 경우는 조금 다릅니다.) 따라서, 여러 개의 class로 이루어진 프로그램의 경우 반드시 시작 class, 즉 java 명령으로 실행할 때에 필요한 이름의 class에는 main 메소드가 있어야 합니다.
C나 C++과 달리 자바에서는 모든 프로그램이 class scope내에서만 정의됩니다. 그러므로 자바에서는 main 메소드도 한 class의 메소드로 정의하게 되어 있습니다. main 메소드의 선언은 다음과 같은 형식으로 정해져 있습니다.
public static void main(String arg[])
만약 main의 선언 중 무엇인가가 틀려서 맞지 않으면 컴파일 때는 문제가 없으나 실행할 때 main의 선언이 잘못되었다는 error가 나오게 됩니다. 예문을 한번 살펴볼까요?
public class HelloWorld {
public static void main(String arg[]) {
System.out.println(" Hello World!");
}
}
앞서 언급한 것처럼 HelloWorld라는 class의 메소드로 main 메소드가 정의되어 있습니다. 이때,
main 메소드를 public으로 선언한 것은 interpreter와 같이 실행 시킬 때 외부에서도 main을 참조할 수 있게 하기 위함이고, static은 HelloWorld라는 instance를 생성하지 않고도 main을 참조하게 해주며 (이것의 자세한 내용은 5장 3절 4. static modifier에서 다룹니다.) void는 return value가 없음을 뜻하는 것입니다.
main 안의 출력 함수인 println()은 System class 안에 있는 out 멤버 변수의 형(type)인 PrintStream object에 포함된 메소드로서 ()안에 포함된 내용을 출력합니다.
main 메소드의 인수인 String arg[]는 command line에 정의된 문자열을 받아들이는 arrary로 arg라는 이름 대신 다른 이름을 써도 괜찮습니다.
컴파일 완료 후
c:\> java HelloWorld seoul pusan
와 같이 실행시키면 arg[0]에 seoul, arg[1]에 pusan 이라는 문자열이 넘어오는 것입니다.
main 메소드 선언 부분을 보면 String 타입의 arrary이 인자값으로 넘어오는 것을 알 수 있습니다. main메소드의 인자값 args[0]는 자바 interpreter 실행시에 인자로 넘어온 값을 의미합니다. 자바 인자값은 자바interpreter와 시작 class를
제외한 나머지를 모두 인자로 넘겨줍니다.
class ArgTest{
public static void main(String arg[]){ // 라인 1
for(int i=0; i < arg.length; i++){ // 라인 2
System.out.println(arg[i]); // 라인 3
}
}
}
위의 코드는 라인 1의 인자값 arg arrary을 이용하여 라인 3에서 인자의 개수만큼 출력시켜보는 내용입니다.라인 2의 length 변수는 arrary의 크기를 나타냅니다. (7절에서 배웠습니다.) 위의 코드를 작성한 후 컴파일합니다.컴파일 완료 후에 아래와 같이 세가지 방법으로 실행합니다.
java ArgTest 하하하 호호호 // 라인 4
java ArgTest 100 + 200 // 라인 5
java ArgTest // 라인 6
라인 4를 실행하면 라인 1의 arg[] arrary에 "하하하", "호호호" 두개의 String 데이터가 arrary을 이루게 되므로 arg.length는 2가 됩니다. arg[0]에는 "하하하", arg[1]에는 "호호호" String을 할당받습니다.
라인 5의 경우 arg.length는 3이고 arg[0]는 "100", arg[1]는 "+", arg[2]는 "200"의String을 할당받습니다. 이 때, 라인 5의 명령 수행시 입력한 100과 200은 숫자가 아닌 String으로 읽혀오므로 자바 프로그램 내에서 다시 원하는 정수나 실수 타입으로 변환하여 사용해야 함을 주의하십시오.
마지막으로 라인 6의 경우에는 프로그램 실행에 필요한 인자값이 입력되지 않았으므로 arg.length는 0 이고 화면에 출력되는 내용은 없습니다.
2) 변수의 초기화자바는 크게 두 가지 종류의 변수를 제공하고 있습니다. 하나는 멤버 변수이고 또 하나는 지역 변수입니다. 이 둘은 서로 사용되는 scope도 다를 뿐더러 초기화에 관련된 사항도 많이 다릅니다.
public class TestVar {
int i;
public static void main(String arg[]) {
....
}
int calcSum() {
int j;
....
}
}
예를 들어 위와 같이 TestVar라는 class를 정의할 때 main 메소드나 calcSum 메소드와 동일한 scope에서 정의된 변수 i는 멤버 변수이며, calcSum 메소드에서 정의된 변수 j는 지역 변수입니다.
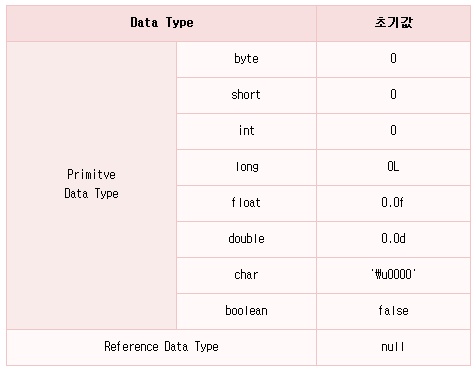
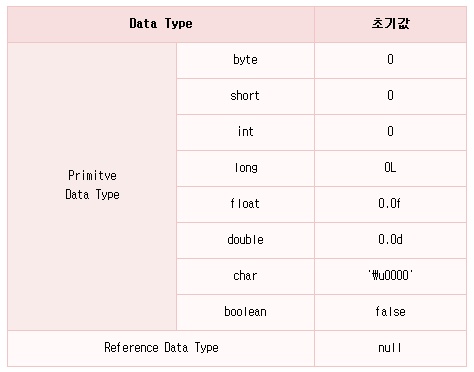
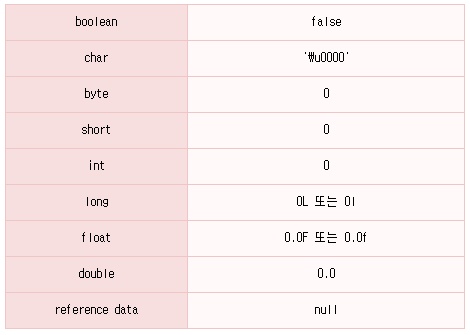
멤버 변수는 class 안의 어디서든 참조 가능하고 한 class 안에서는 global하게 값이 유지됩니다. (단,static으로 선언된 메소드에서는 non static인 멤버 변수를 access 할 수 없습니다. 자세한 내용은 5장 4절3주제 static modifier에서 설명합니다.) 그리고 멤버 변수가 선언되어 생성된 후 별도로 초기값을 지정하지 않으면 선언한 Data Type에 따라 다음과 같은 default 값을 초기값으로 갖게 됩니다.
Array가 생성될 때 갖는 초기값들과 같은 초기값들이죠?
이와는 달리 지역 변수는 한 메소드 scope 안에 선언된 변수들을 말하는 것으로, 메소드가 호출되었을 때 stack에 생성되었다가 수행이 완료되면 없어지는 성격을 가지고 있습니다. 때문에 지역 변수를 automatic 변수라고도 부릅니다. 이런 지역 변수는 선언되었을 때 멤버 변수와는 달리 시스템에 의해 자동적으로 초기화 값이 주어지지 않습니다. 그래서 자바는 컴파일할 때 초기화를 하지 않고 사용하는 지역 변수는 전부 error로 처리합니다.
public class TestVar {
int sum;
public static void main(String arg[]) {
TestVar t = new TestVar();
System.out.println("SUM=" + t.calcSum(10));
}
int calcSum( int lim ) {
int i = 0; // 라인 1.
int result; // 라인 2.
if (true) {
while (i < lim) {
result = result + i;
i++;
}
}
return result;
}
}
위와 같은 예문을 컴파일하면 지역 error 메세지가 발생할까요? 안 할까요?
이러한 상황의 프로그램에 대해서도 컴파일러는 지역 변수를 초기화하지 않았다는 error 메세지를 발생할 것입니다. 당연하겠죠.하지만, 지역 변수를 선언하고 초기화 하지 않았더라도, 사용을 하지 않으면 컴파일 에러는 발생되지 않습니다.
변수를 선언한다는 것은 사용하기 위한 메모리가 잡히게 되는 것이고, 초기화를 한다는 것은 이를 사용하기 위해 미리 메모리를 정리한다는 의미입니다.
멤버변수는 초기화를 자동적으로 해주니까 문제가 없는데, 지역 변수는 초기화가 자동적으로 되지 않으므로 별도로 사용하기 전에 초기화를 하지 않으면, 그 메모리 영역에 어떤 값이 들어가 있으지 모르겠죠. 이 메모리에 들어있는 정리되지 않은 값, 즉 쓰레기 값을 가지고 동작을 시키려면 어떻게 상황이 발생될 지 모르죠. 이를 막기위해서 초기화되지 않은 지역 변수 사용을 컴파일러가 에러를 발생시키면서 수정하도록 만들어 에러를 미리 방지하는 것입니다.
하지만, 선언만 해놓고 사용하지 않는다면 컴파일시 문제는 없지만 while 구문안의 result = result + i; 라인을 없애보고 컴파일하면 어떻게 되는지, 한 번 테스트 해보세요.
3) 자바의 멤버변수와 지역변수자바에서는 어디에서 변수를 선언할까요?
자바에서의 변수 선언은 { }으로 묶여있는 곳이라면 어디에서나 가능합니다. C나 C++의 경우 변수 선언 외의 실행문이 나오기 전에 모든 변수가 선언되어야 합니다. 그러나 자바에서의 변수 선언은 어디에서나 가능합니다.
for(int l = 200; l < 500 ; l++){
int j = l * 300;
while ( j < 800){
int k = 500;
}
}
위의 코드를 살펴보면 for문 내에서 int 타입의 변수 l, j가 선언되어 각각 초기화된 후 사용됩니다. 이렇게 { } 내에서 선언된 변수를 지역변수(local variable)이라고 합니다. { } 내에서 선언된 지역 변수는 { } 지역을 벗어나면 자동으로 삭제됩니다.
while(true) {
int var1 = 200;
while (true) {
int var2 = 300;
System.out.println(var1); // 라인 1.
System.out.println(var2); // 라인 2.
break;
}
System.out.println(var1); // 라인 3.
System.out.println(var2); // 라인 4.
}
위의 코드를 살펴보면 라인 1 문장은 라인 1을 포함한 while을 포함한 외부 while 블록에서 선언된 변수var1을 사용하므로 올바른 코드입니다. 라인 2 문장은 라인 2 문장을 포함한 while 블록에서 선언된 변수 var2를 사용하므로 역시 올바른 코드입니다. 라인 3 문장은 라인 3 문장을 포함한 외부 while 블록(첫문장) 내에서 선언된 변수var1을 사용하므로 역시 올바른 코드입니다. 마지막으로 라인 4 문장은 내부의 while 블록에서 선언된 var2가 내부while 블록을 종료하면 더 이상 사용할 수 없는 변수이므로 error가 발생합니다.
class LocalTest{
String s = "member 변수"; // 라인 1
public void m1(){
System.out.println(s); // 라인 2
}
public static void main(String args[]){
String s = "main 메소드의 local 변수"; // 라인 3
System.out.println(s); // 라인 4
System.out.println(new LocalTest().s); // 라인 5
}
}
위의 코드를 살펴보면 라인 1에서 선언되어 초기화된 s 변수가 m1 메소드 내의 라인 2 문장과 main 메소드 내의 라인 5 문장에 의해 사용됩니다. 라인 1의 s 변수는 class가 정의되면서 class { } 내에서 사용할 수 있도록 정의한 것입니다.
이러한 타입의 변수는 class 내에서 멤버 변수(Member Variable)라고 합니다. 그리고 라인 3 문장에 의해main 메소드 내에서도 같은 이름의 변수 s가 선언되어 초기화되었습니다. 라인 3의 s 변수는 main() 메소드 블록 내에서만 사용할 수 있는 변수입니다.
예문에서 살펴보았듯이, 변수가 선언되는 지역에 따라 멤버 변수인지, 지역 변수인지 나눌 수 있습니다. 멤버 변수는 선언된 class 내의 어디에서나 사용될 수 있고 지역 변수는 그 변수가 선언된 블록({ }) 내에서만 사용합니다. 그리고 멤버 변수는 선언과 동시에 자바 컴파일러에 의해 묵시적으롤 초기화값을 할당받습니다. 그러나 지역 변수는 묵시적인 초기화가 이루어지지 않으므로 반드시 프로그래머가 명시적으로 초기화값을 할당하여야 합니다.
각 데이터 타입에 따른 묵시적인 초기화값은 다음과 같습니다.
class LocalTest{
String s ; // 라인 1
public void m1(){
System.out.println(s); // 라인 2
}
public static void main(String args[]){
String s ; // 라인 3
System.out.println(s); //라인 4
System.out.println(new LocalTest().s); //라인 5
}
}
라인 1의 멤버 변수 s 는 라인 2와 라인 5가 실행되면 묵시적으로 null로 초기화되므로 null을 출력합니다. 라인 3의main 메소드의 지역 변수 s는 선언만 하고 초기되지 않았습니다. 지역 변수는 묵시적으로 자동 초기화되지 않으므로 라인 4에서 출력되지 않고 에러가 발생합니다.
10. 매개변수 전달방식1) 매개변수란?메소드가 호출 될 때 값을 주어야만 호출 되어지는 것을 쉽게 볼 수 있습니다. 만일, 아래와 같이 선언된 add 메소드가 있다고 가정해 보겠습니다.
int add(int x, int y)
이 메소드를 호출하려면 x, y값을 두개를 넣어 주면 add이라는 메소드는 내부적인 작업을 끝마친 뒤 x와 y를 더해서 return을 하게 됩니다. 이 때 우리는 x, y를 매개 변수라고 합니다. x, y는 add 메소드의 호출과 동시에x, y를 메소드의 내부에서 생성하게 되며 외부에서 넘어오는 값을 중간에서 할당 받게 됩니다. add(1, 2)라고 호출한다면x에는 1이 직접 할당의 방법으로 할당되고 y에는 2가 할당 되어집니다.
int a;
a=8;
......
int add(int x, int y){
return x+y;
}
......
add(1,2);
그럼 언제 매개변수를 사용할까요?
이에 대한 답은 필요하다고 생각 될 때 메소드를 만드는 프로그래머가 만들면 됩니다.
그럼 매개변수는 몇 개까지 사용할 수 있을까요?
이에 대한 답은 역시 필요하다고 생각 될 때 필요한 만큼의 개수까지 사용할 수 있습니다. 즉, 무제한입니다.
메소드의 이름은 매개변수와 결합하여 변수의 역할을 수행하므로 매개변수의 개수와 데이터 형을 맞추지 않으면 메소드는 호출할 수 없습니다. 이 때, 매개변수의 데이터 형은 반드시 지켜야 합니다. 즉, 매개변수는 메소드 내에 만들어지지만 외부로부터 값을 받을 수 있는 유일한 통로입니다.
2) Primitive Data Type 매개변수다음의 프로그램을 살펴보며 Primitive Data Type 매개변수를 사용할 때 발생되는 결과를 알아보겠습니다.
public class TestParam {
public static void main(String arg[]) {
int ival = 0;
TestParam mainobj = new TestParam(); // 라인 1.
mainobj.effectParam(ival); // 라인 2.
System.out.println("main ival: "+ ival);
}
void effectParam(int ival) {
ival = 300;
System.out.println("sub ival: "+ ival );
}
}
C를 조금이라도 해 본 분들은 이 프로그램의 실행 결과를 예측하실 것입니다. (call by value)
sub ival: 300
main ival: 0
main 메소드에서 0의 값을 가진 ival 변수를 매개변수로 하여 effectParam 메소드를 호출하면 (이미scope가 다르기 때문에) effectParam 메소드에서 사용하기 위한 복사본이 만들어집니다. 즉, effectParam메소드에서 사용하는 ival은 main 메소드에서 전달한 ival의 값을 그대로 갖는 별도의 메모리를 할당하여 사용하는 것으로서effectParam 메소드의
실행이 끝나 return 되면 메모리에서 자동적으로 사라집니다. 그러니 main 메소드의 ival은 당연히 아무 영향도 받지 않게 되는 것이지요.
3) Reference Data Type 매개변수이번에는 Reference Data Type 매개변수를 사용한 프로그램을 살펴볼까요 ?
public class TestParam {
public static void main(String arg[]) {
Param p = new Param(); // 라인 1.
TestParam mainobj = new TestParam();
p.ival = 100;
mainobj.effectParam(p); // 라인 2.
System.out.println("main ival: "+ p.ival);
}
void effectParam(Param p) {
p.ival = 300;
System.out.println("sub ival: "+ p.ival);
}
}
class Param { // 라인 3.
int ival;
}
자, 여기서는 Param이란 새로운 class를 정의하고(라인 3) Param class의 object를 생성한 후(라인1) 이를 매개변수로 effectParam 메소드를 호출하였습니다.(라인 2) 이와 같은 프로그램의 결과는 어떻게 나올까요?
sub ival: 300
main ival: 300
main 메소드에서 Param class type으로 선언된 p는 new 문에 의해 생성된 Param object의 주소 값을 갖게됩니다.
따라서 이러한 p가 effectParam 메소드에 매개변수로 전달 되는 것은 Param object의 주소 값을 전달하는 것이므로 (effectParam 메소드에서 p가 local 변수이긴 하지만) 결국 main 메소드의 p와 effectParam의p는 동일한 Param object를 point하게 됩니다.
그러므로 effectParam 메소드에서 Param object의 ival을 300으로 바꾼 것은 (비록effectParam 메소드의 실행이 끝나 return 되면 p는 메모리에서 자동적으로 사라진다하더라도) main 메소드의 p가 포인트하고 있는 Param object의 값을
변경한 것이 되는 것입니다.
public class TestParam {
public static void main(String arg[]) {
Param p = new Param();
TestParam mainobj = new TestParam();
p.ival = 100;
mainobj.effectParam(p);
System.out.println("main ival: "+ p.ival);
}
void effectParam(Param p) {
p = new Param(); // 라인 1.
p.ival = 300;
System.out.println("sub ival: "+ p.ival);
}
}
class Param {
int ival;
}
앞에서 살펴 본 프로그램에 라인 1을 추가한다면 어떤 결과가 나올까요? (실제로 만들어 한번 테스트해 보세요.)
sub ival: 300 main ival: 100
이와 같은 결과가 나오는 이유는, p를 매개변수로 전달 받을 때 까지는 main 메소드의 p가 포인트하는 Param object의 주소를 갖고 있었지만, 라인 1을 통해 새로운 Param object를 만들어 이것의 값을 바꾼 것이기 때문입니다. (참고적으로 effectParam 메소드에서 새로 생성한 Param object는 return 되면서 바로Garbage collection의 후보가 된답니다.)








 JAVA의 정석.pdf
JAVA의 정석.pdf














